Asteroid Mining Analysis
In this project, I analyzed asteroid data, from NASA's Jet Propulsion Laboratory, to assess their suitability for mining. By comparing factors such as size, material composition, and orbital paths, I identified promising asteroid groups. Leveraging deep learning models, I imputed missing values for geometric albedo and diameter parameters. Valuable insights were gained through statistical analysis.
Task
Analyze asteroid data and determine feasibility of mining operations
- Asteroid size vs Distance from earth: Larger asteroids have more resource, but do we have to go far to mine from large asteroids?
- Material composition vs Distance from earth: Metallic asteroids have more valuable materials, how does near earth asteroids compare to ones further away?
- Orbital period vs Distance from earth: Are valuable asteroids more frequently orbiting earth or passing by earth?
Asteroid data was collected from NASA's Jet Propulsion Laboratory
- The dataset contained more than 1 million unique asteroid data.
- Each row had 30 attributes describing its size, orbital properties, material composition, reflectance, and more.
Nearly 99.99% of light reflectance data is missing. And about 80% of geometric albedo and diameter values were missing.
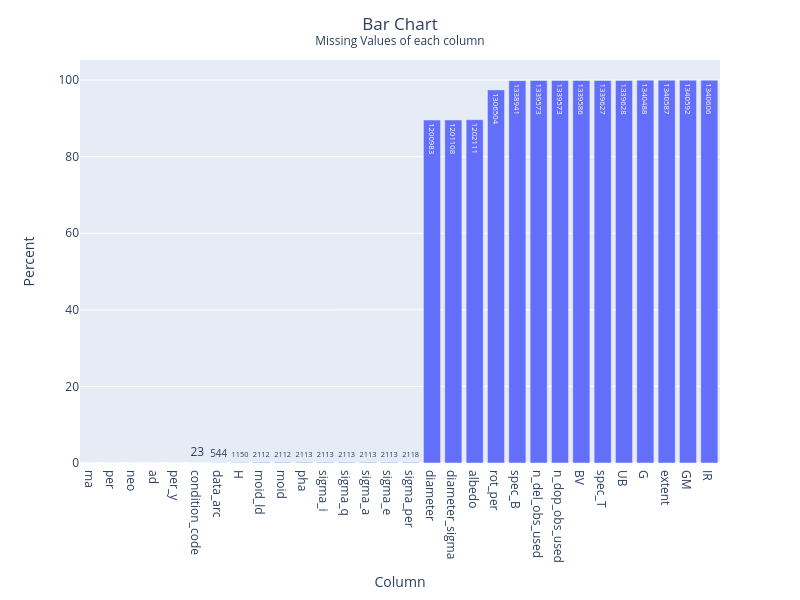
Action
Data Preparation
Impute by Group
Columns with relatively few missing values (< 5%) was imputed with their
- Mode for categorical columns (condition code, class, is_neo, etc.)
- Median for numerical columns (orbital period, MOID, etc.)
Categorical columns were imputed first. Then they were used to group rows together for imputing by median.
Impute using Neural Networks
Two attributes, albedo and diameter were extremely important for this project.
- Albedo is needed for identifying material composition data.
- Diameter is used to infer size of the asteroids.
Two Multilayer Perceptrons trained on the cleaned data was used predict and impute missing values.
Feature Engineering
Used existing attributes to construct explainable and important features. For example:
- From Eccentricity to Orbital Shapes (Circular or Parabolic?)
- From Albedo to Material composition (Metallic or Carbonaceous?)
- From periphellon and aphellon distance to NEO asteroid type
Outlier Removal
Statistical tests are sensitive to outliers. Thus before proceeding with statistical analysis, I've removed outliers from the dataset. Outliers were identified using five number summary method.
Statistical Analysis
Size Analysis
-
On average which near earth
asteroid type has larger asteroids?
- ANOVA test to identify if all groups have same mean size. (Because groups have similar distributions)
- Pairwise t-test to identify ordering amongst types.
-
On average which asteroid belt
has larger asteroids?
- Kruskal-Wallis test to identify if all groups have same median. (Because groups have different distributions)
- Two-sample t-tests to identify ordering amongst belts.
Composition Analysis
-
Are asteroids near earth more
metallic (and thus more valuable)?
Two-sample proportion test between metallic and non-metallic asteroids.
-
Which NEO type has higher
metallic asteroids?
- Goodness-of-fit test to if all types have similar proportions.
- Pairwise two sample proportion tests to identify ordering amongst types.
- Which belt has higher proportion of metallic asteroids? Pairwise two sample proportion tests to identify ordering amongst belts.
Orbital Period Analysis
-
Which NEO type has the shorter
orbital period (and thus is observed more
frequently)?
- ANOVA test to see if all types have the same average orbital period.
- Pairwise t-tests to identify ordering amongst types.
- Does orbital period vary greatly for different composition types?
-
Does metallic asteroids have
shorter periods?
Welch t-test to identify if metallic asteroids have a lower orbital periods.
Factor plot and 2-way ANOVA test to see if orbital periods vary significantly for different compositions.
Result
Size Analysis
- Looking at asteroid size (measured by diameter), Apollo asteroids are generally bigger than other NEO types. Bigger asteroids have more materials to mine, and Apollo asteroids come closer to Earth than others. So, it's logical to begin with Apollo for mining operations.
- In the future, when we have the right technology for space exploration, our focus should be on the main asteroid belt (MBA) instead of the outer asteroid belt (OAB) This is because asteroids in the MBA are larger than those in the OAB
Composition Analysis
- NEOs generally have a smaller percentage of metallic asteroids compared to those farther away. However, within NEOs, the Apollo asteroids stand out with the highest proportion of metallic asteroids. This makes them an excellent starting point for mining efforts.
- In the future, our focus for mining should be on the main belt asteroids They have the highest percentage of metallic asteroids compared to asteroids in other belts.
Confusion Matrix
- Amor asteroids usually have the shortest orbit periods, but they are actually the farthest from Earth. In contrast, Apollo asteroids have longer orbit periods but are the closest to us.
- Looking at the material composition, metallic NEO asteroids, on average, have shorter orbit periods than carbonaceous asteroids. This implies that we can mine metals from asteroids more often due to their more frequent orbits.
Lessons Learnt
Outliers detection and removal = More reliable statistical tests
Outliers heavily affect the result of hypothesis tests like the Welch t-test.
Framing questions as hypothesis tests
Questions often needed to be reframed so that it aligns well with hypothesis tests.
Parametric VS Non-parametric tests
Depending on the knowledge of data distribution, appropriate type of tests needs to be selected.