Kaggle Automated Essay Scoring 2.0
In this competition, we had to score essays on a scale of 1 to 6. The scoring criteria needed to be consistent with the holistic scoring criteria. Using an ensemble of DeBERTa and Light Gradient Boosted Trees The competition is still running and once it's over I'll update my final ranking.
Task
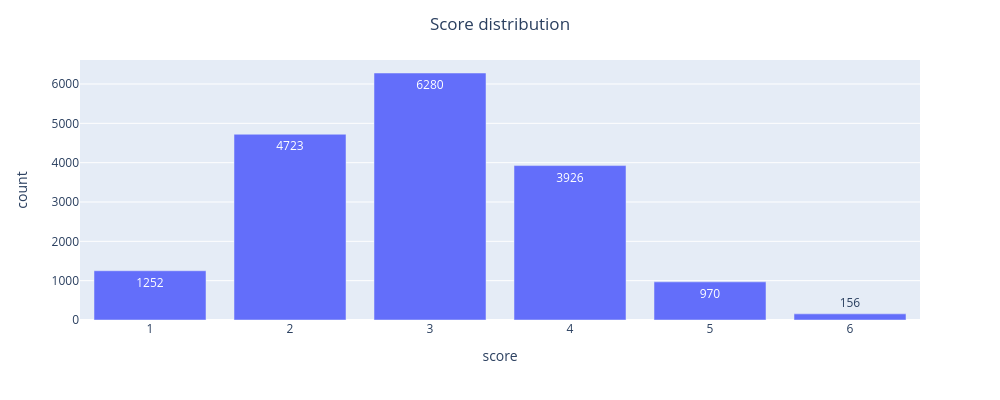
Score essays holistically on a scale of 1 to 6
The difference between ground truth and predicted score should be as minimal as possible. For example:
| Prediction Qaulity | Ground truth | Predicted |
|---|---|---|
| Perfect | 5 | 5 |
| Bad | 5 | 3 |
| Worse | 5 | 1 |
- Training data consisted of 17 thousand hand written and AI generated essays on 7 topics.
- The hidden test set consisted of 7 thousand unseen essays, some of which were on different topics entirely.
Action
Data Preparation
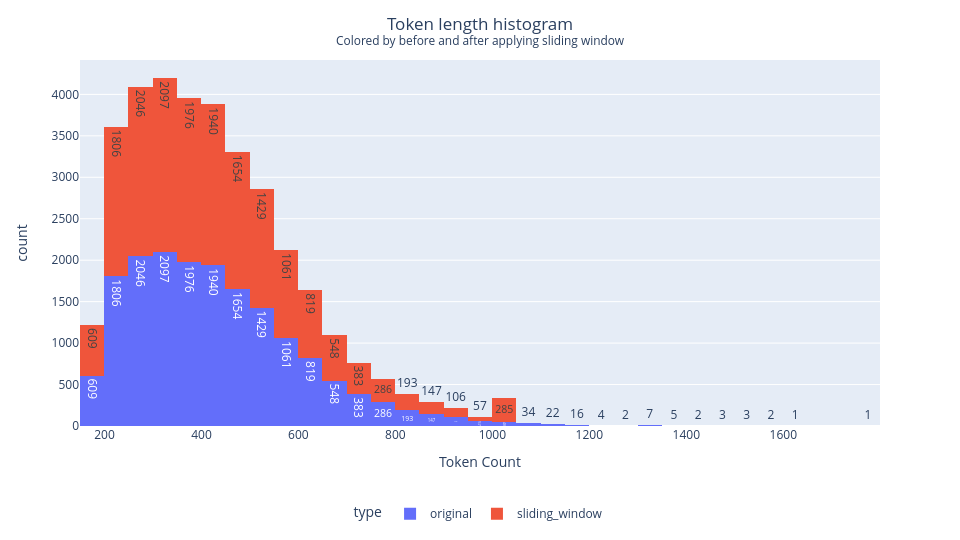
Sliding Window
Divide long essays into windows of length 1024 tokens.
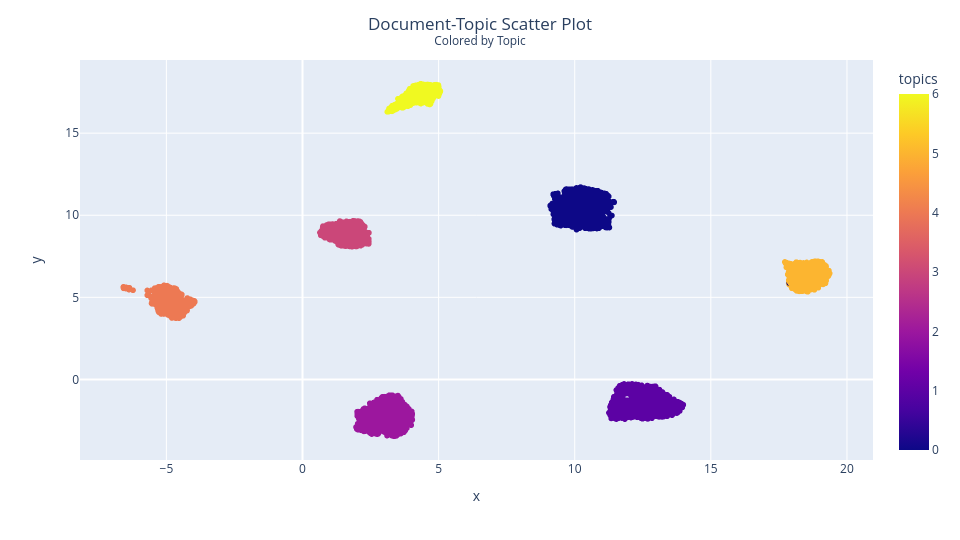
Topic Modeling
Identifying overall topic of the essays and cluster them accordingly.
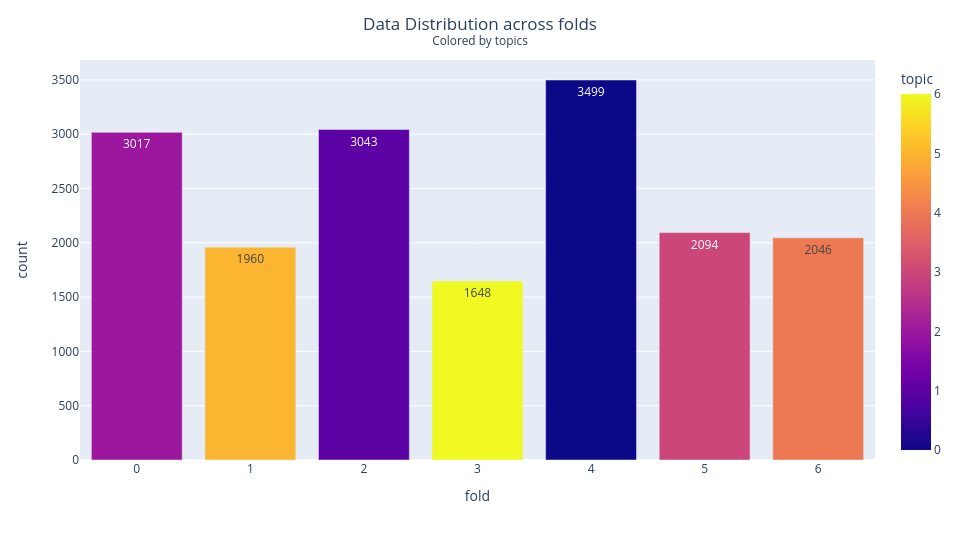
Cross Validation Strategy
Stratified 7-fold CV grouping by topic for DeBERTa models.
Feature Engineering
Basic statistical descriptors (mean, max, sum) for token (character, word, sentence).
TF-IDF and cTF-IDF vectors
Uncommon word count, mispelled word count, grammar score, etc.
Predictiion
Microsoft's DeBERTa-V3-Large predicted score probabilities only from essay text.
Predicted score from DeBERTa ensemble probabilities and engineered features.
Result
Experimentation was tracked using Weights and Biases to quickly iterate and improve predictive performance. Additional experimentation details and results can be found in the repository wiki. Cross-validation performance for a select few experiments are shown below:
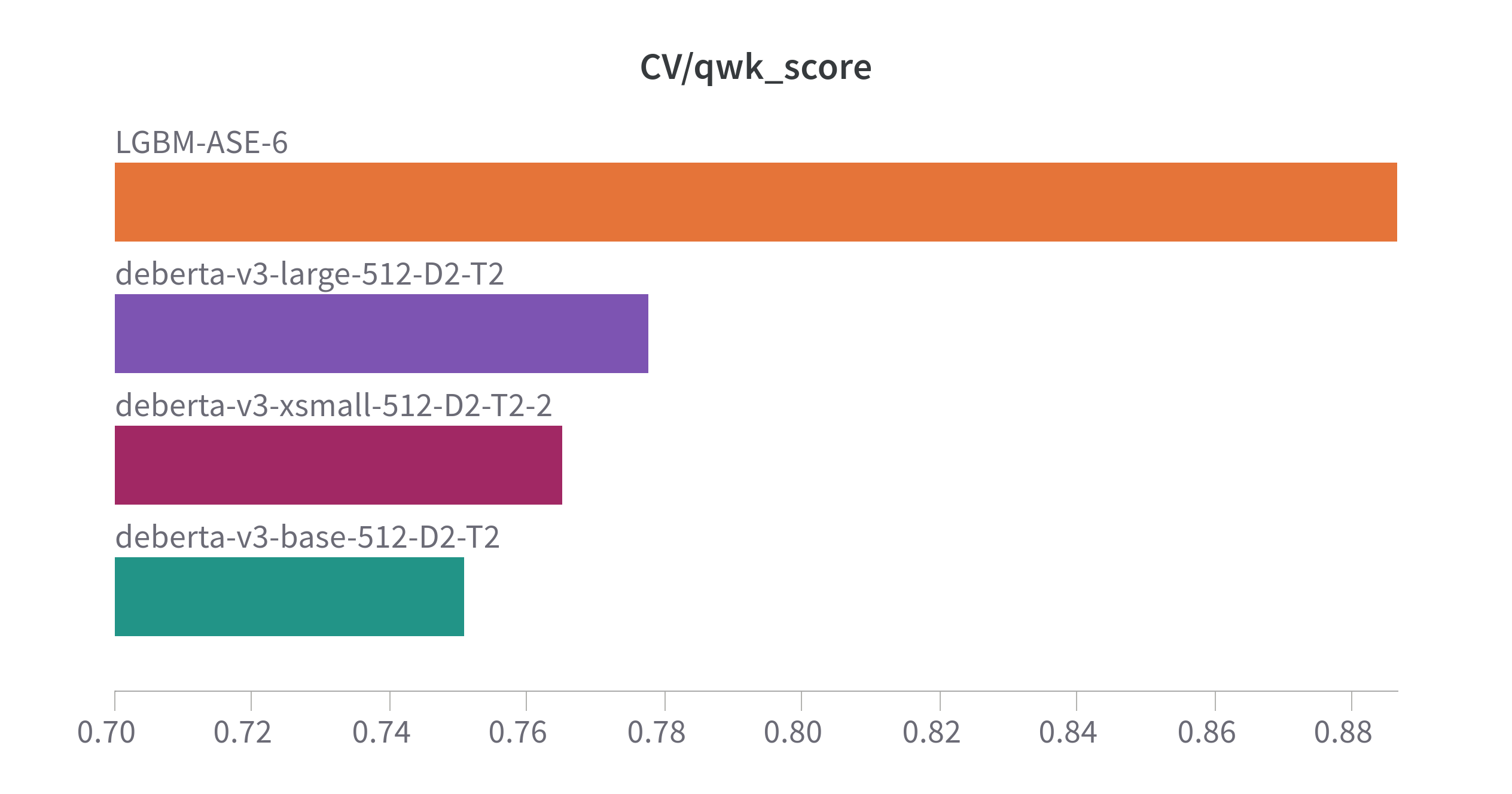
QWK Score
Combining LGBM and DeBERTa ensemble gives the best performance
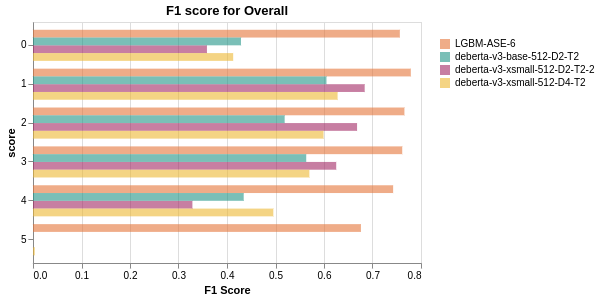
F1 Score
LGBM has high classification performance across all classes.
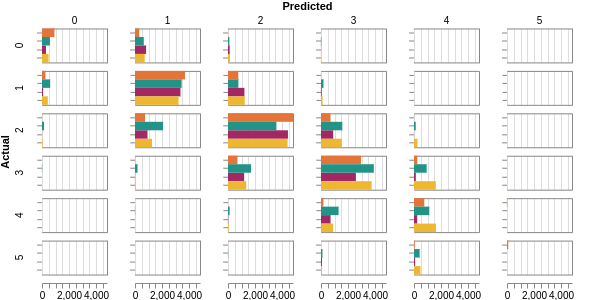
Confusion Matrix
Predicted scores have minimal difference from ground truth.
The best system so far has score 0.793 in the public leaderboard.
Lessons Learnt
Engineering good features = great performance
Well engineered features coupled with Deep Neural Networks outperform standalone deep neural networks.
Poor CV Strategy = Bad Leaderboard Performance
Kaggle competitions require a good CV strategy that correlates well with public leaderboard. In the beginning, I had a poor CV strategy where I got great CV performance but terrible leaderboard performance.
Iterative Improvement Requires Experiment Tracking
Over the span of 2 months, I experimented a lot. Tracking the experiment parameters like data version, model version, configurations, etc. in a platform helped immensely in prototyping.