Kaggle PII Detection
This was my very first Kaggle competition where I had to detect Personally Identifiable Information (PII) from essays written by students. The main challenge of the competition was dealing with the extreme skew in the dataset. Essays with thousands of words had very few PII, if any at all. My solution was to use negative sampling, thresholding, and ensemble of multiple DeBERTa models to predict tokens as PII. Ultimately, it ranked 173rd out of 2100 participants, earning me a bronze medal.
Task
Detect PII from long text sequence
The system is penalized 5 times more for missing a PII than falsely detecting one. Recall is 5X more important than precision.
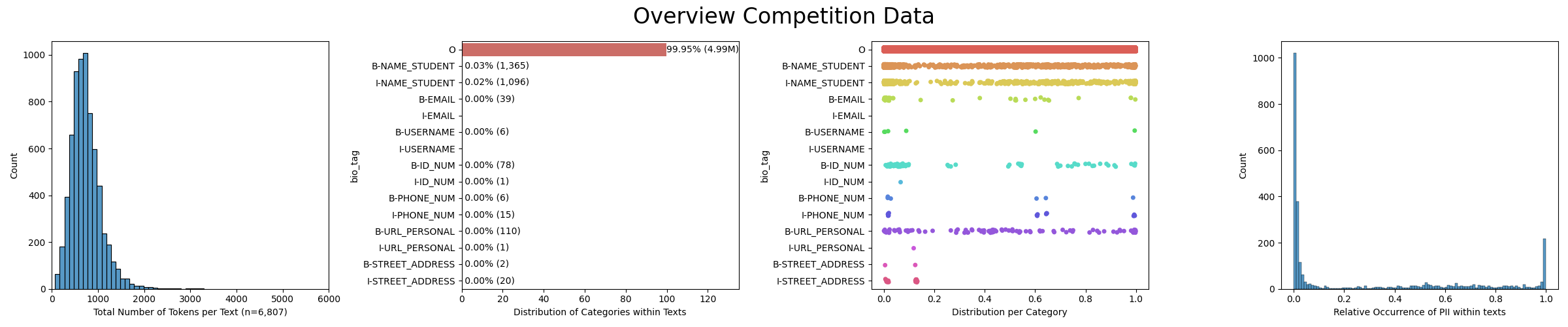
The competition dataset comprises approximately 22,000 essays written by students. 30% of this data is usable as a training set, 70% of this data is kept as the leader test set.
7 PII types with each type further being split into beginning or intermediate PII types. For example:
| Seqeunce | My | name | is | Shakleen | Ishfar | and | my | is | shakleenishfar | @gmail.com | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PII Prediction | O | O | O | B-NAME | I_NAME | O | O | O | O | B-EMAIL | I_EMAIL |
Action
Data Preparation
Sliding Window
Instead of using long sequence lengths, I divided them into overlapping windows of length 512. This allowed me to train models with smaller context window while retaining high performance.
Synthetic Data Generation
Competition data lacked every type of PII data. To have the model recognize all 7 variations of PII data, I synthetically generated essays with PII using Mixtral-8x7B.
Negative Sampling
70% of examples didn't have a single PII. I divided these into 3 separate datasets and then added positive samples to them. This reduced the skewness and resulted in better performing models.
Prediction
Weighted Loss Updates
As recall is 5 times more important than precision, I wanted to minimize false negatives. Thus, I set class "O" with a very low weight for loss updates, as 99.9% of tokens were of this class and it wasn't PII.
Experiment Tracking and Hyperparameter Tuning
Experiments were tracked in Weights and Biases platform. Keeping track of data versions and configurations allowed me to quickly prototype and improve my system. Furthermore, hyperparameter tuning was used to determine optimal values.
Ensemble 3 DeBERTa Models
I trained 3 separate DeBERTa-V3-Base models using 3 different folds of the negative sample coupled with the same positive samples. The final ensemble of models was used for inference.
Post-processing
Thresholding
If probability of not being a PII is less than 70% then assign the token as a PII. This improves the model's recall metric even more.
Regular Expression
Used Regular Expressions to detect Email, Username and Phone number type PII tokens, as they followed a particular pattern.
Assigning "B-" and "I-" tags
Iteratively assigned "B-" and "I-" prefixes based on PII indices. As a result, misclassification between "B-" and "I-" types drammatically decreased.
Result
Overall the system performs well on the validation dataset. It achieved 0.96 F5 score in the validation dataset. This translated to 0.953 on the leaderboard hidden test dataset. As shown in the 2nd graph below, it is clear that the model achieved 0.9+ F5 score for all the PII types.
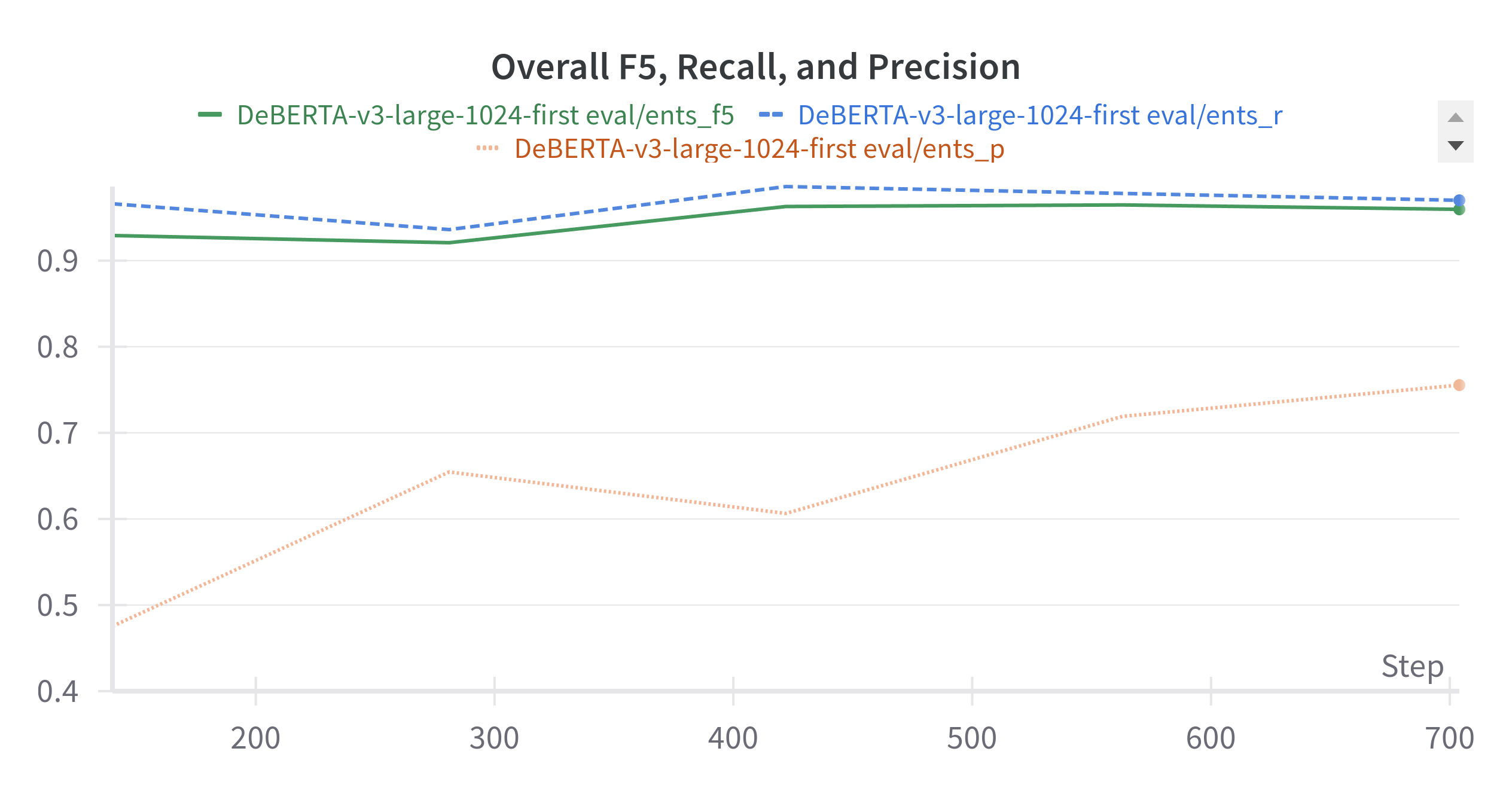
Overall F5 Score
The model has high recall and lower precision. But as recall is 5X more important, it achieves a high F5 score.

PII-wise F5 Score
The model manages to get high F5 score of 0.9+ for all the PII types.
The system ranked 173rd out of 2048, which got me a bronze medal.
Lessons Learnt
Good quality data = Great Performance
Thoughout the competition, I experimented with external datasets from multiple sources. The best model used only one external dataset that was of the highest quality, instead of using more data. Thus, data quality matters a lot more than quantity in this task.
Handling Extreme Class Imbalance
The major challenge of this competition was handling the extreme class imbalance. I learnt to use techniques like negative sampling, thresholding, ensembling, and weighted loss updates to tackle this issue.
Iterative Improvement Requires Experiment Tracking
Over the span of 2 months, I experimented a lot. Tracking the experiment parameters like data version, model version, configurations, etc. in a platform helped immensely in prototyping.