News Outlet Freedom Detection
In this study, I investigate the extent of press freedom in national news media outlets. To achieve this, I analyze the sentiment and editorial stance of news articles across specific topics covered by both national and international media. Subsequently, I conduct rigorous statistical tests to identify significant differences in various factors such as mean values, variance, and correlations. When statistically significant distinctions emerge, I formulate a hypothesis suggesting that the national media outlet lacks press freedom. To validate my findings, I evaluate the effectiveness of my system using data from the national media of three countries: China, Russia, and Canada.
Task
Quantify press freedom
To compare national and international media, I chose sentiment and stance scores.
- Sentiment tells me whether the news is positive (+1), neutral (0), or negative (-1).
- Stance tells me whther the news is published in favor of (+1), impartial (0), or against (-1) the national government.
I compare articles from both sources when they fall under the same broad topic. For example, political articles are compared to each other.
I run multiple statistical tests like Welch test, variance test, etc. to find statistically significant distinctions amongst the scores.
I limited my the scope of the project to three national and two international media outlets:
| Country of Interest | National | International |
|---|---|---|
| China | The China Daily | Reuters and AP |
| Russia | The Moscow Times | Reuters and AP |
| Canada | CBC | Reuters and AP |
Action
Data Preparation
Data Collection
Scraped data from news websites using Selenium. For each country, nearly 10K articles were collected..
Data Cleaning
Performed text level processing (removing HTML tags, URLs, etc.), row level processing (removing duplicates, empty content, etc.), and country specific processing (removing non-english characters).
Topic Modeling
Performed topic modeling using BERTopic for each country separately to cluster similar articles into a broad topic, such as politics, sports, finance, security, etc.
Sentiment and Stance Scoring
Prompt Engineering
Utilized Prompt Perfect to engineer an effective prompt for LLM to predict sentiment and stance from an unbiased perspective. Imtegrated advanced prompt engineering tactics like chain of thought, role assignment, etc.
Finetuning Dataset Creation
Utilized GPT-3.5 Turbo to create a finetuning dataset using 300 articles. The articles were uniformly selected from each country and each source.
LLaMa-2 Training and Inference
Finetuned LLaMa-2 and utilized the LLM to predict sentiment and stance scores on a scale of -1 to +1. Additionally, extracted the LLM's reasoning behind said prediction.
Statistical Tests
Measure of Centrality
Ran Welch and Wilcoxon tests to indetify significant distinctions in mean and median scores.
Measure of Spread
Carried our 2-sample F-test to measure difference in score variance.
Correlation
Performed Pearson's and Spearman's correlation test to see whether the scores were correlated in anyway.
Result
Global News has freedom of press
Most statistical tests fail to find significant distinctions. National media cover more crime news than international. And Weather and Telecommunication doesn't have sufficient samples.
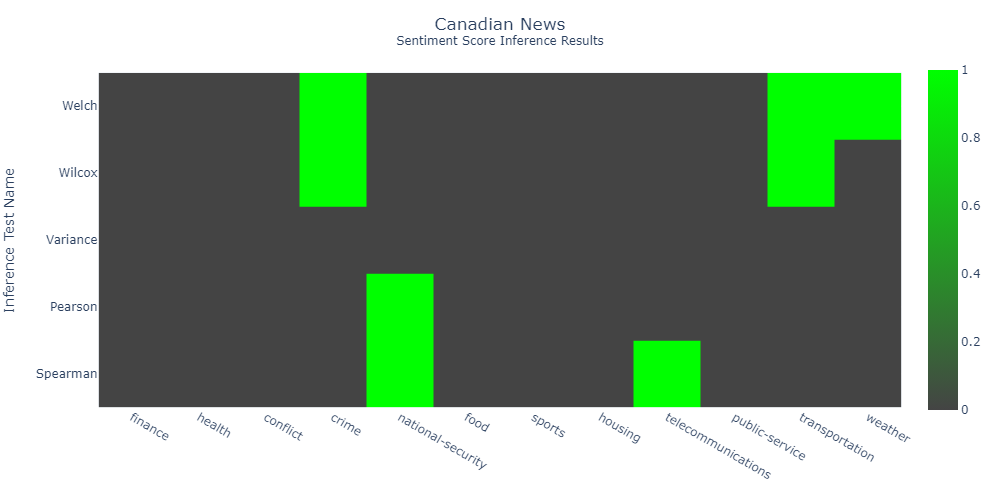
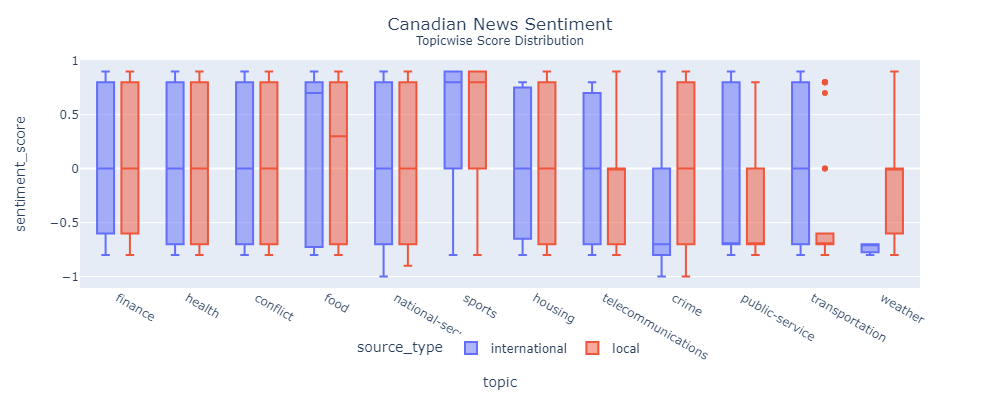
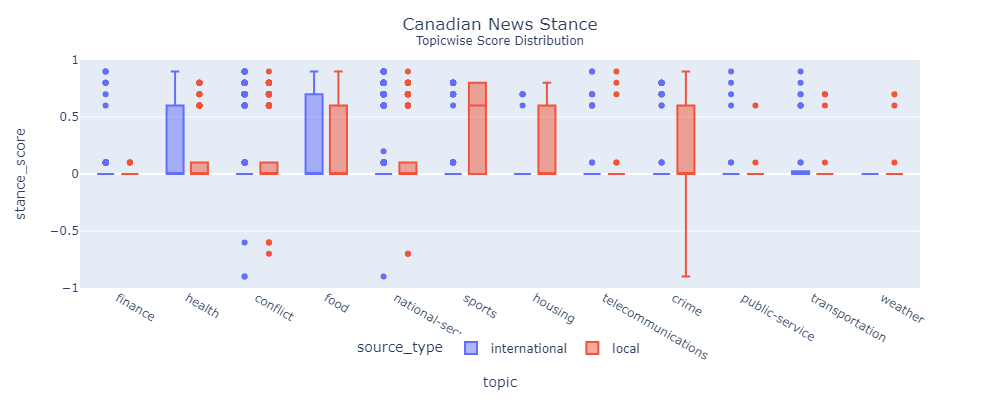
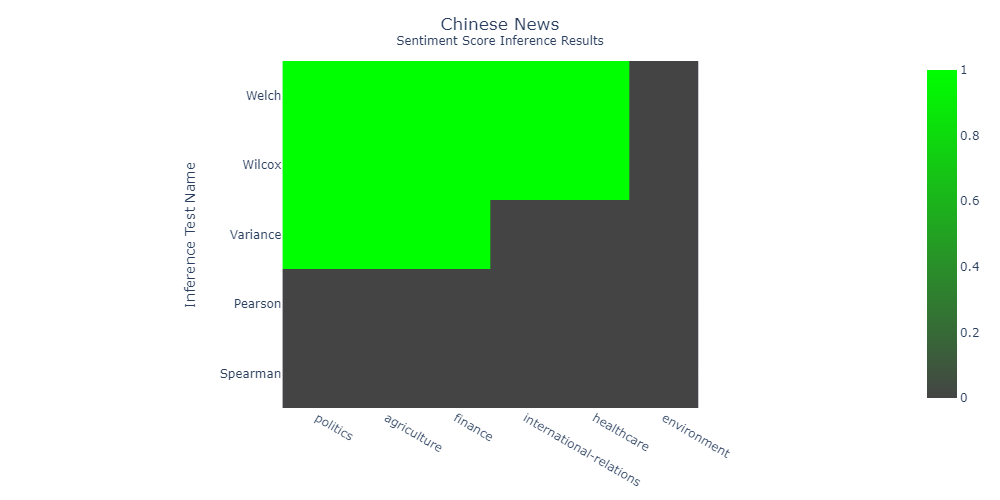
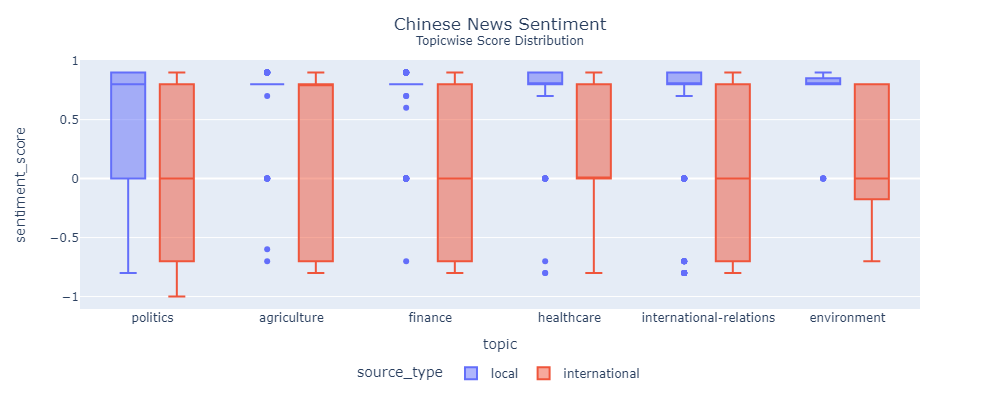
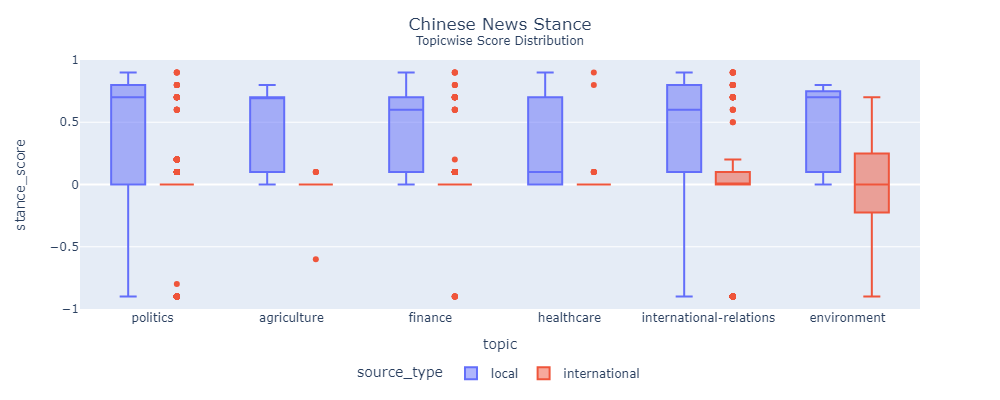
China Daily doesn't have freedom of press
National news is mostly positive and in favor of the government. The statistical tests heatmap is mostly green, which means that distinctions were significant.
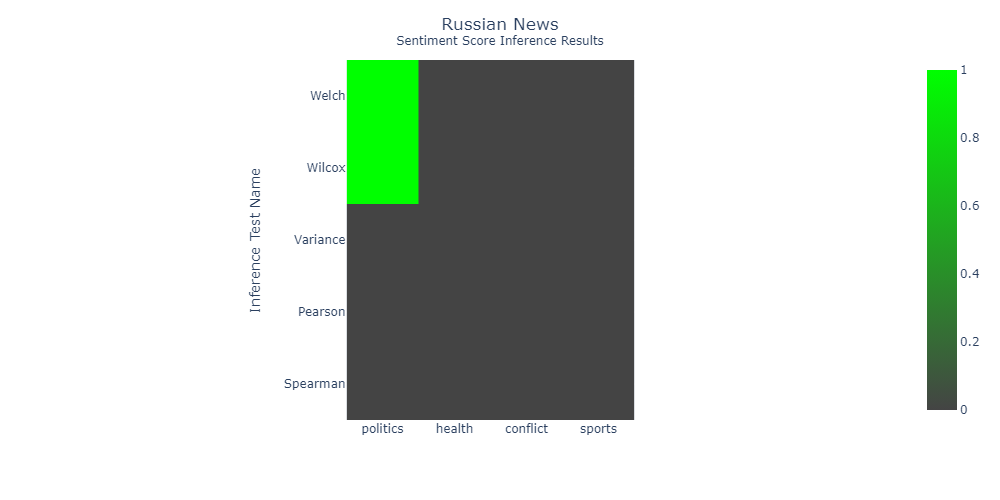
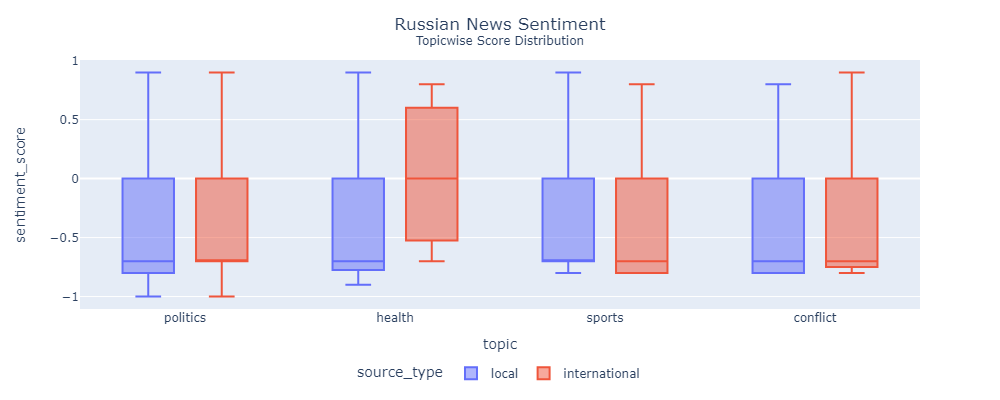
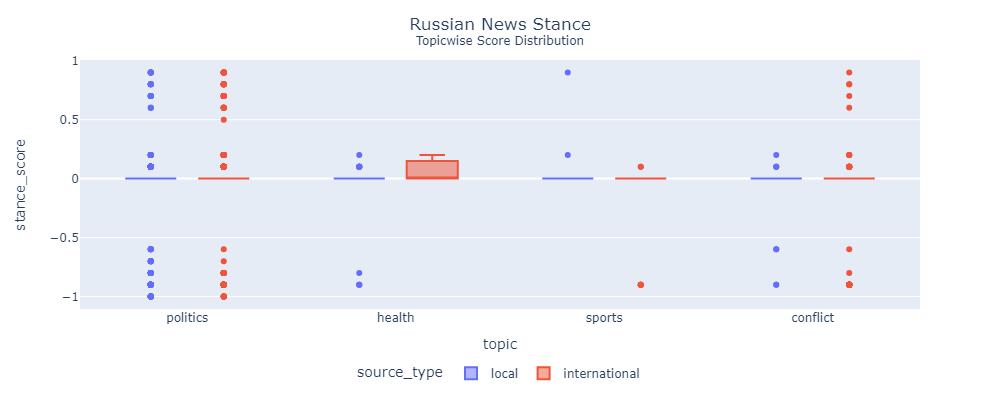
I'm unsure about The Moscow Times
Most of the news is focused around the war. As a result there is very few news about other topics. Which is why the results are unreliable.
Lessons Learnt
LLM's depend on great prompt
To leverage the powerful capabilities of LLMs careful prompt engineering is required.
Clean Data = Good Performance
Significant effort is needed to clean text data. Sentiment and stance scores are unreliable when run on noisy text data.
Understanding hypothesis tests
The result of hypothesis test depends on many factors like sample size, confidence level, test design, etc. How I interpret the results and draw conclusions.