End-to-End Tweet Sentiment Analysis
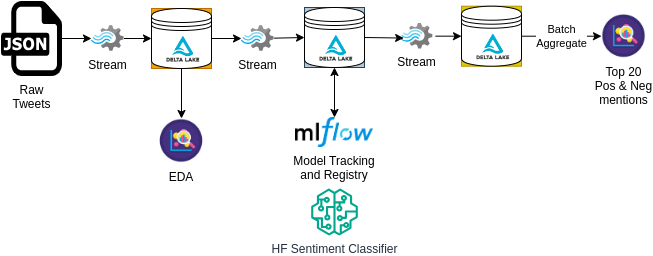
In this project, I developed a comprehensive system to analyze tweet sentiment using Spark. Initially, I ingested raw data and filtered it to create a bronze table in Delta Lake format. After performing ETL (Extract, Transform, Load) and data cleaning, the bronze table was transformed into a silver table. We employed a BERT model to predict tweet sentiment, saving the results in a gold table. Prediction metrics, such as F1 score and the confusion matrix, were tracked using MLFlow. Additionally, I analyzed five common performance issues—spill, skew, shuffle, storage, and serialization—and made adjustments to minimize their impact. Finally, we used the gold table to analyze sentiment patterns across tweets and users.
Task
Build a scalable system to analyze tweet sentiment
Build reliable and performant data pipelines using Delta Lake. The pipeline is composed of three layers:
- Bronze layer: Raw ingested data
- Silver layer: Cleaned and filtered data
- Gold layer: Curated business level data

Track metrics of deep learning model using MLFLow and use it to perform sentiment detection on the dataset.
- Identify the 5S of performance issues in Spark which are Spill, Storage, Skew, Serialization, and Shuffle.
- Take steps to reduce their impact on the Spark application.
Action
Medallion Architecture Construction
Raw tweet data is read as a stream that is constantly updated with new tweets. I used Delta Lake technology to save data at various stages of the pipeline as bronze, silver, and gold tables.
Inference using a traditional UDF is slow. I used Pandas UDF to leverage Apache Arrow and Pandas vectorization capabilities to speed up inference procedure.
A BERT model from HuggingFace was used for sentiment classification. This model was stored in MLFlow registry and performance metrics related to the model were tracked using MLFlow as well.
Identify and Minimize Performance Bottlenecks
Shuffle partitions were set to be a multiple of the number of cores in the workers. This minimized spill perforamnce issue.
Delta tables were optimized to reduce small files issue. Furthermore, Z-ordering was used to make fetching relavant data more optimal.
Pandas UDF was used to minimize serialization bottleneck as much as possible. Although the function isn't as efficient as native spark functions, its still much more efficient than traditional UDFs.
Lessons Learnt
Medallion Architecture
Structuring the data pipeline using the medallion architecture made it convenient for data management when I had to go back and check data from an earlier stage in the pipeline.
MLFlow Tracking
Tracking performance metrics in MLFlow allowed me to compare different version of the model.